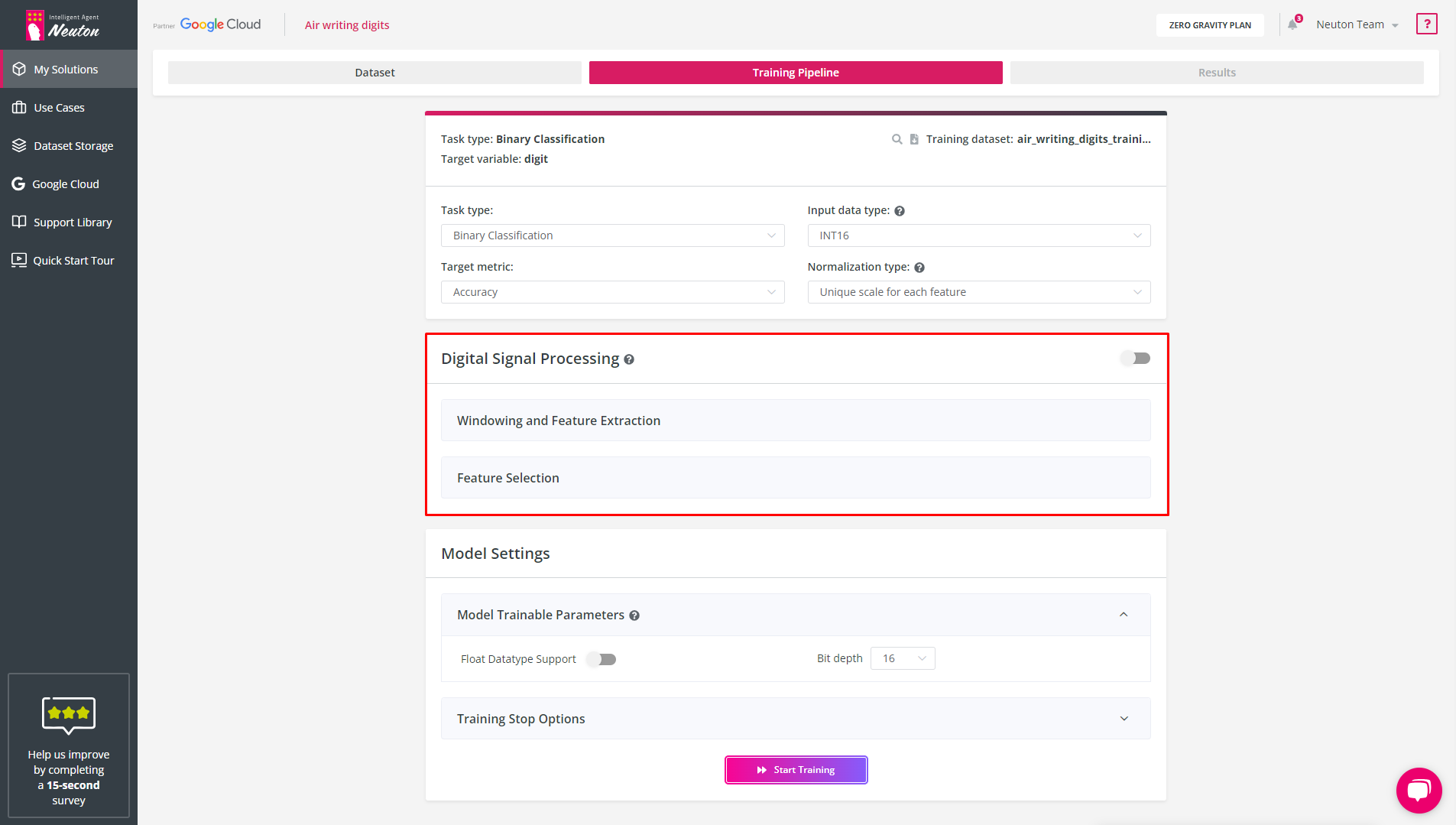
Digital Signal Processing (DSP) option enables automatic processing of raw data and feature extraction for data from gyroscopes, accelerometers, magnetometers, electromyography (EMG), etc.
Features created in Feature Extraction will be normalized within their own scale
Raw data will be normalized within the scale of each variable/axis from which they were extracted
Windowing & Feature Extraction
This option transforms the signal data into a vector with a specified window size, and also enables users to generate additional variables of their choice.
Windowing
Window size is the portion of data that will be used for processing the training dataset (the static window approach is applied on the platform). It should be universal for all events in the training dataset, even if the duration of events is different. Therefore, for correct training of the model, the data in the training and the validation datasets (if applicable) must be brought to the same window using upsampling or downsampling, before loading into the platform.
Using the window size, the training dataset will be grouped by a selected number of samples. All variables extracted from the raw data will be calculated from these groups. For correct feature calculation, the recommended minimum window size is 5 samples/rows.
Since the platform is intended for solving TinyML tasks, it is recommended that the maximum window size does not exceed 1000 samples/rows. However, it all depends on your data and there are no technical restrictions on the window size in the platform.
You have 3 options for the windowing specification:
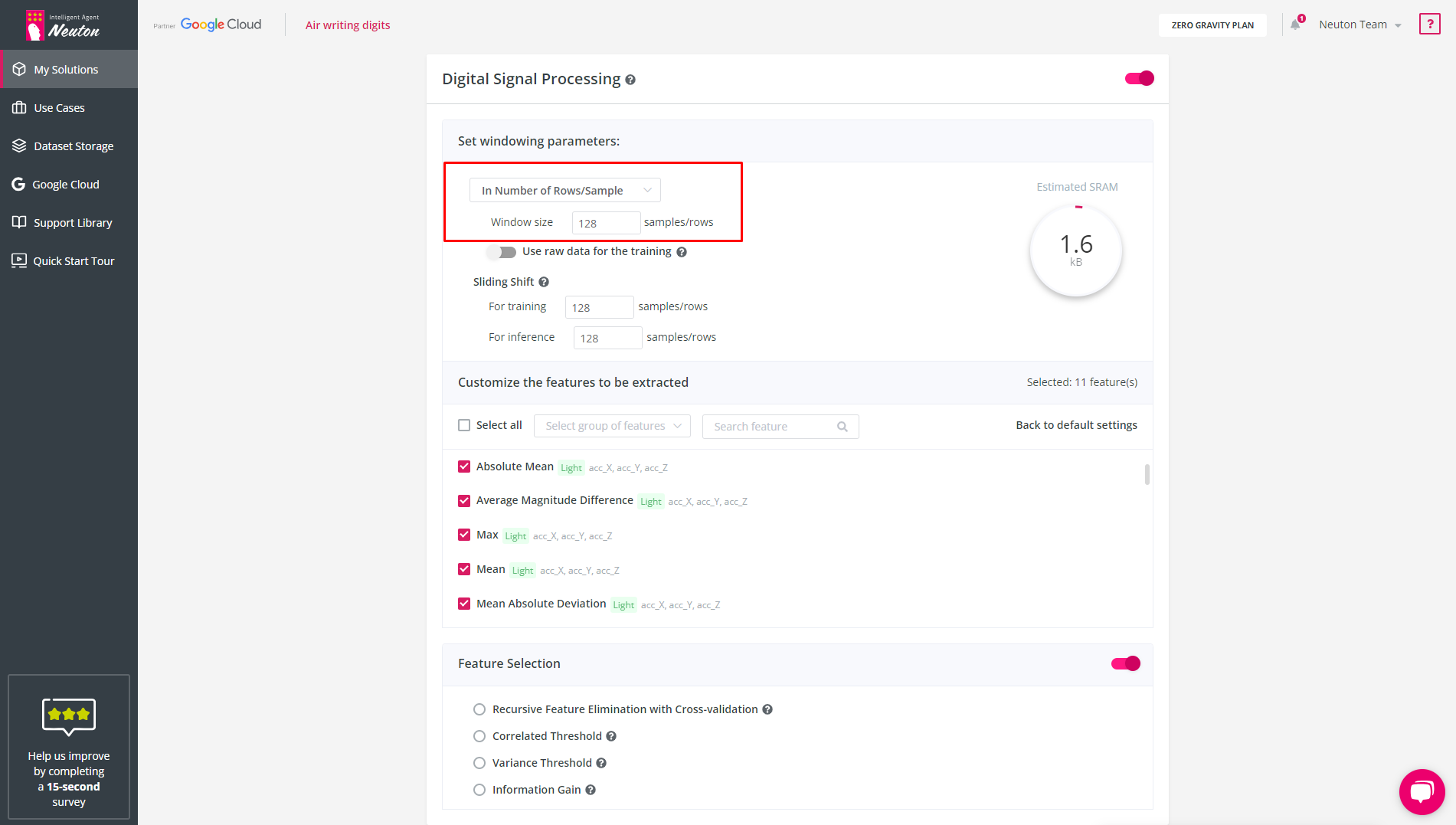
In Number of Rows/Samples
![]()
In Number of Rows/Samples
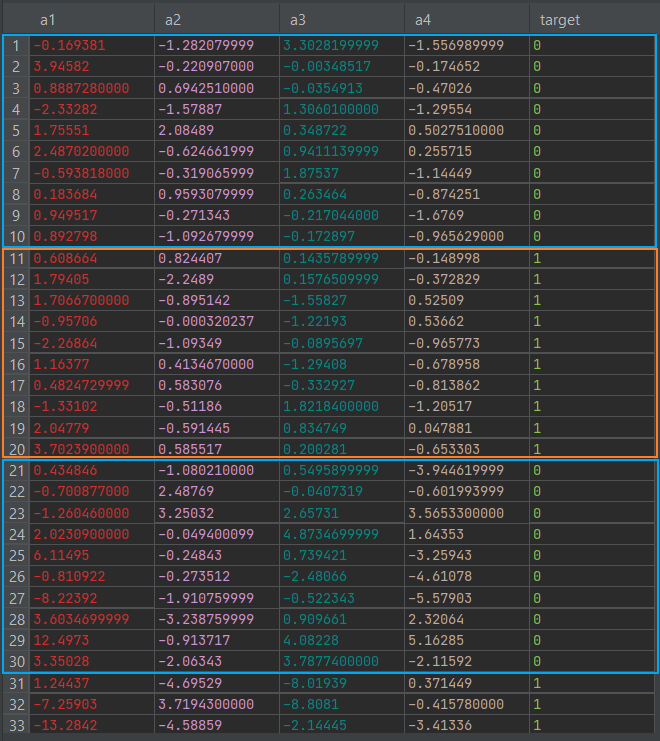
The platform default is 128, but you can specify the count of rows to use for windowing. For example, for the following dataset:
![]()
the window = 10 samples
![]()
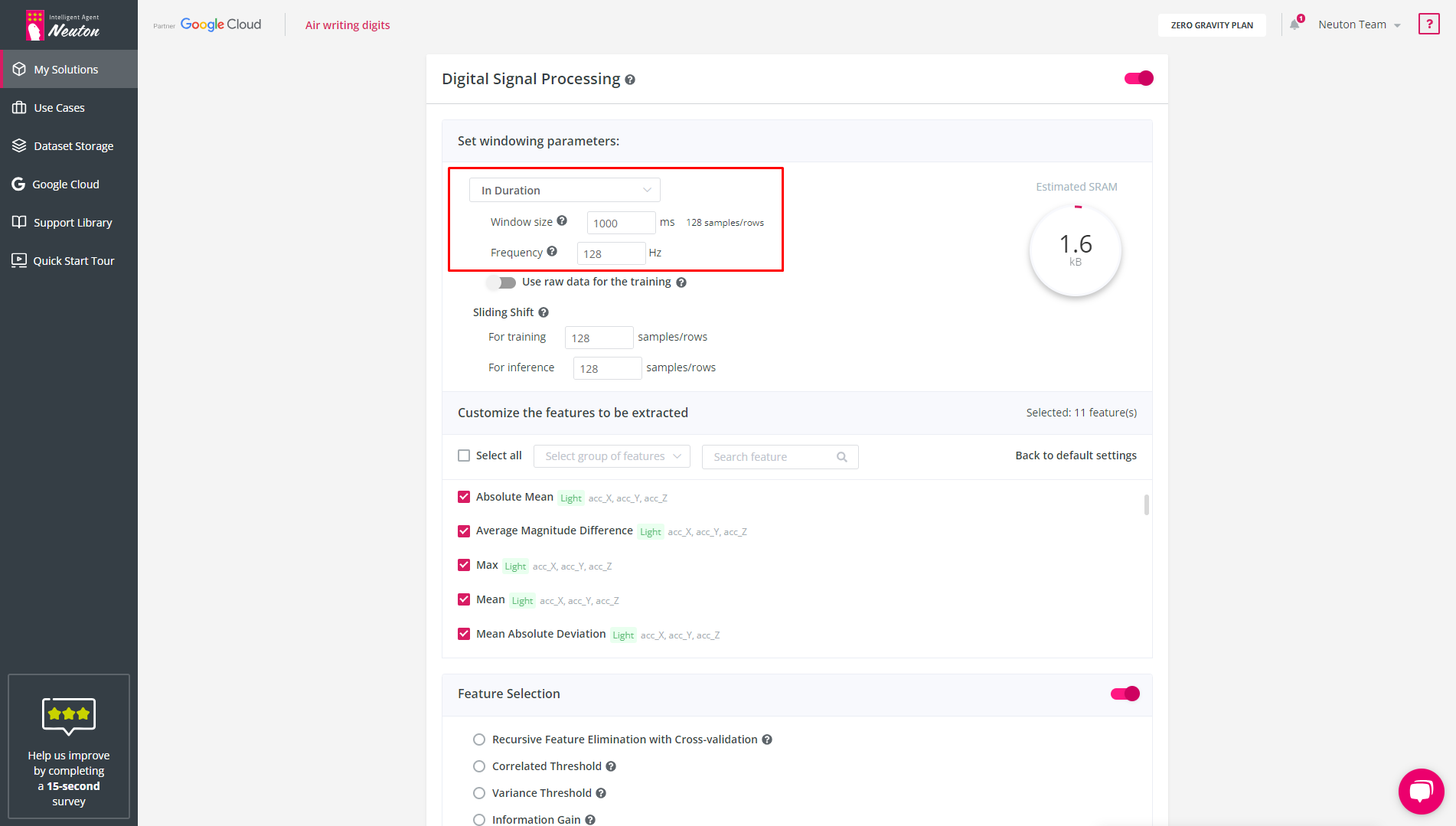
In Duration
Specify window size in ms and frequency in Hz to define window size for the training dataset.
If you use sensors with different frequencies, then you must first bring all signals to a single frequency using downsampling or upsampling.
According to the specified data, the platform will determine the size of the window in samples/rows and it will be used in the future to calculate features and other operations.
![]()
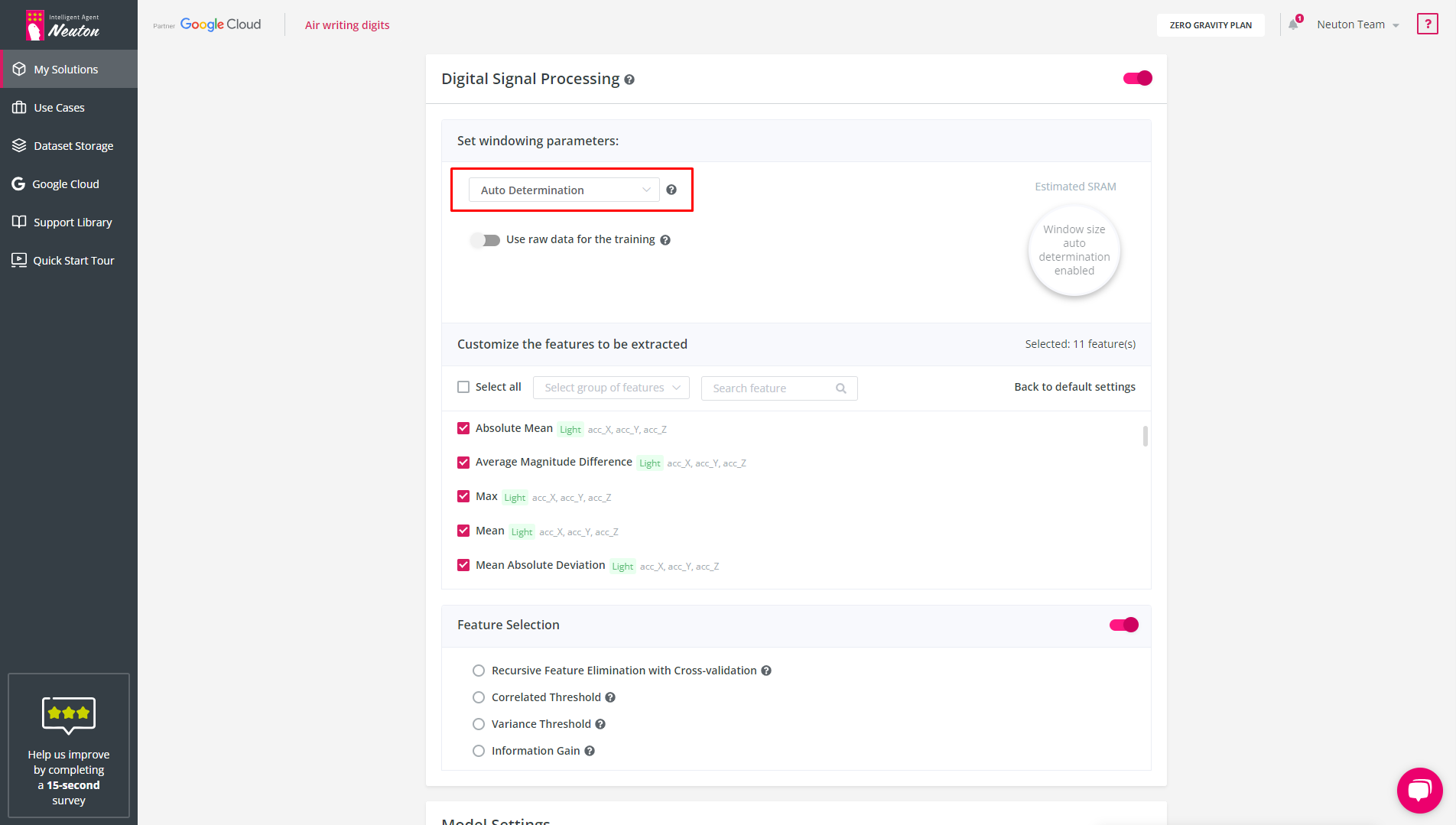
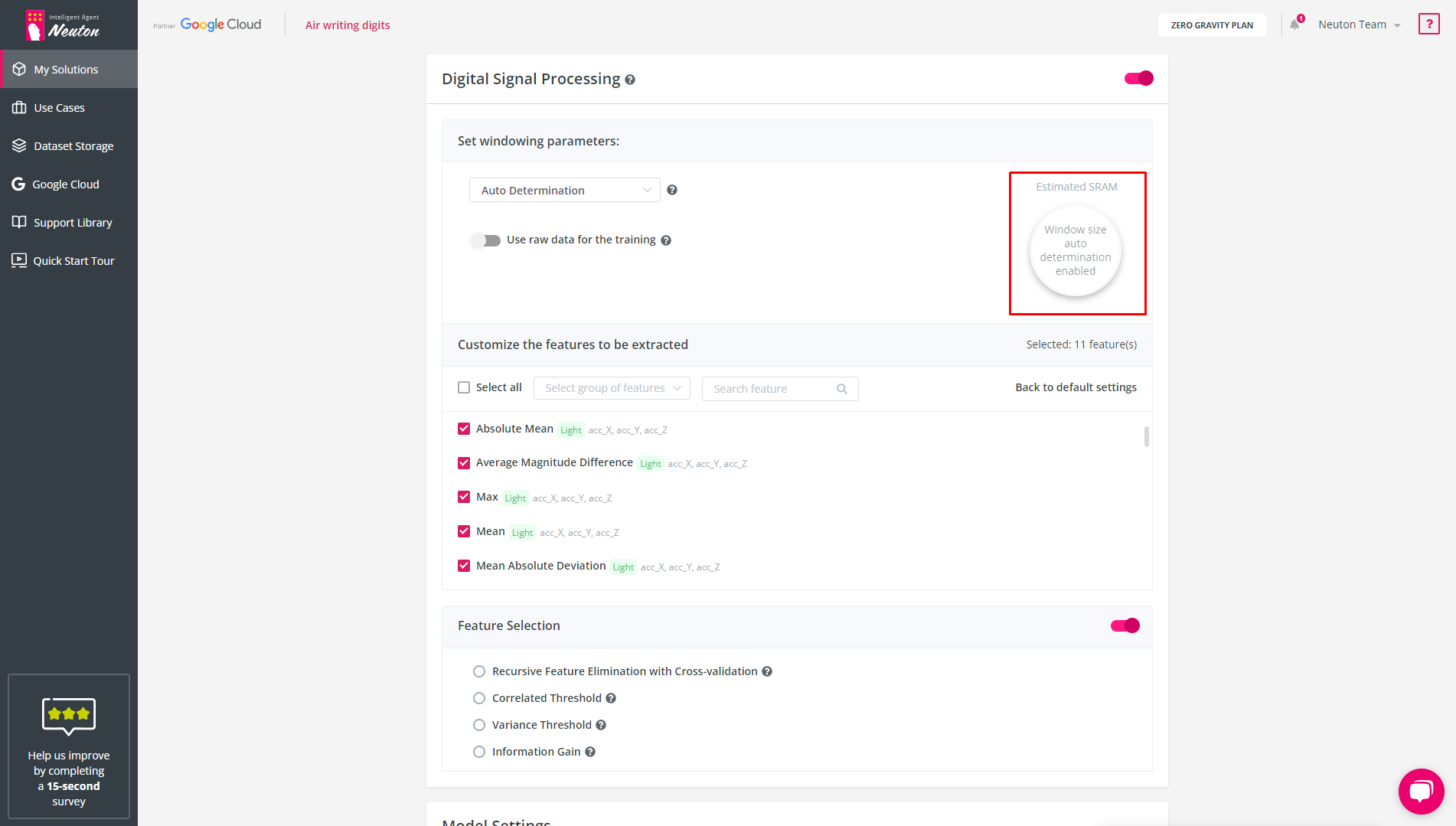
Auto Determination
Using Fast Fourier Transform this option automatically selects the window size based on the best model quality (this option is available only for the classification task type). For finer tuning of SRAM usage, it is recommended that you manually enter the window size and frequency of data.
If you plan to use frequency features to solve your problem, then the window size should be a multiple of a power of two.
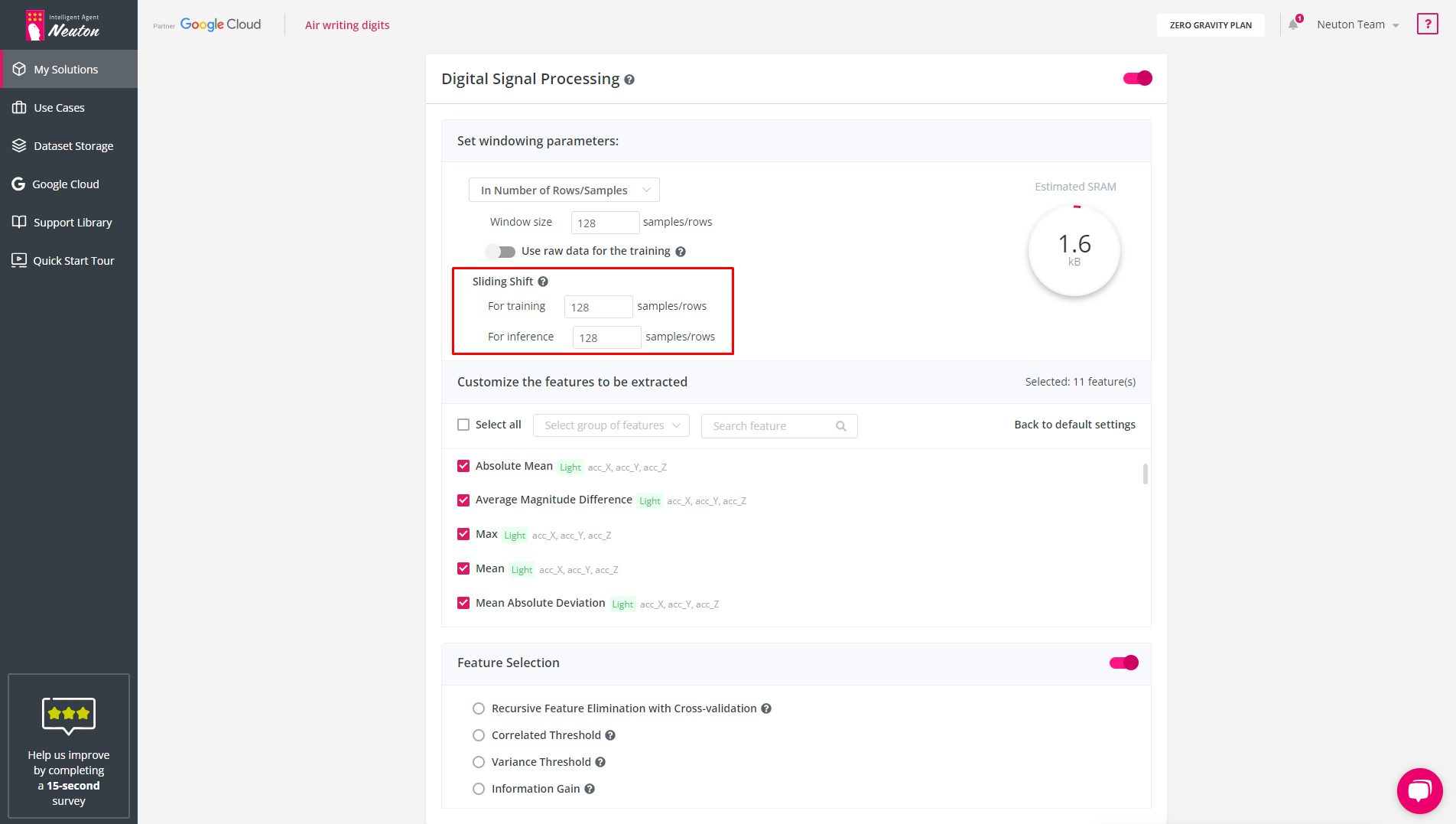
Sliding Shift
![]()
Sliding Shift
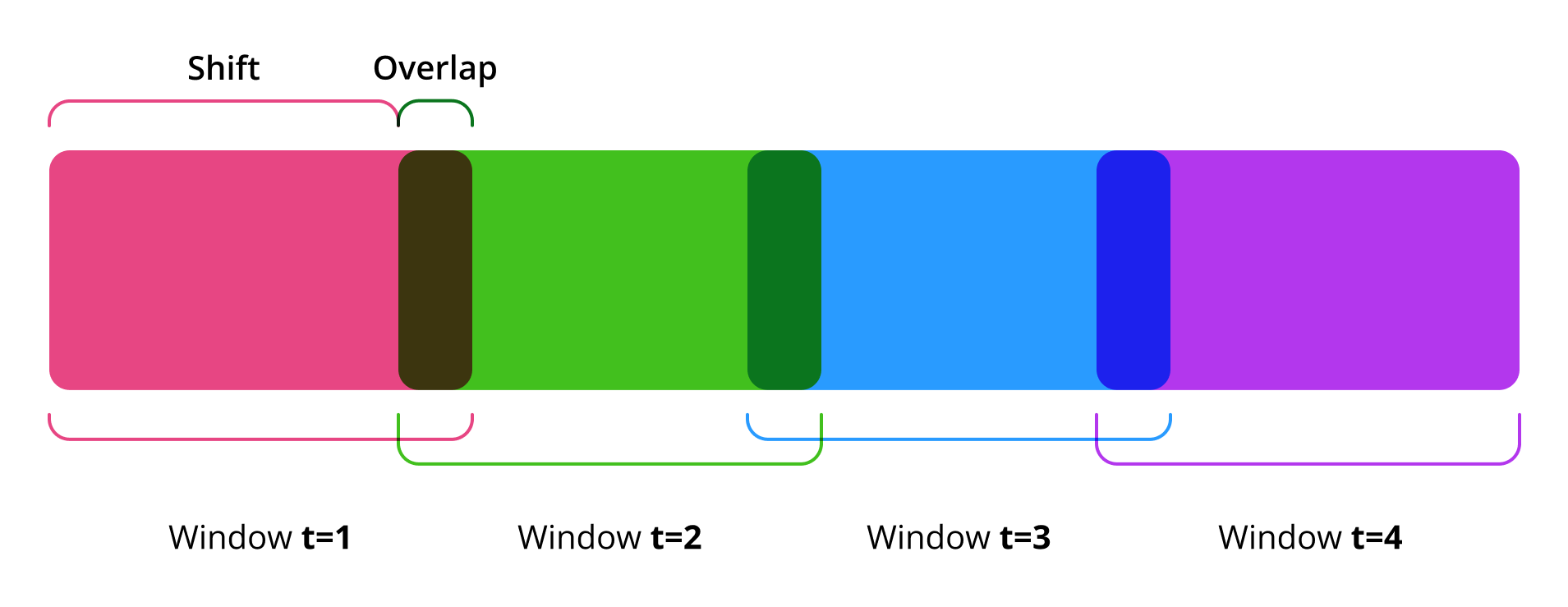
The sliding shift is used for the window overlap and indicates how many rows/samples are needed to shift to form the next window. It is available for both training and inference. If the sliding shift values are equal to the window size, then the window segmentation is performed without an overlap.
![]()
Sliding Shift
The options' value can't exceed the specified window size. When window size auto-determination is enabled, the sliding shift values are set automatically equal to the window size.
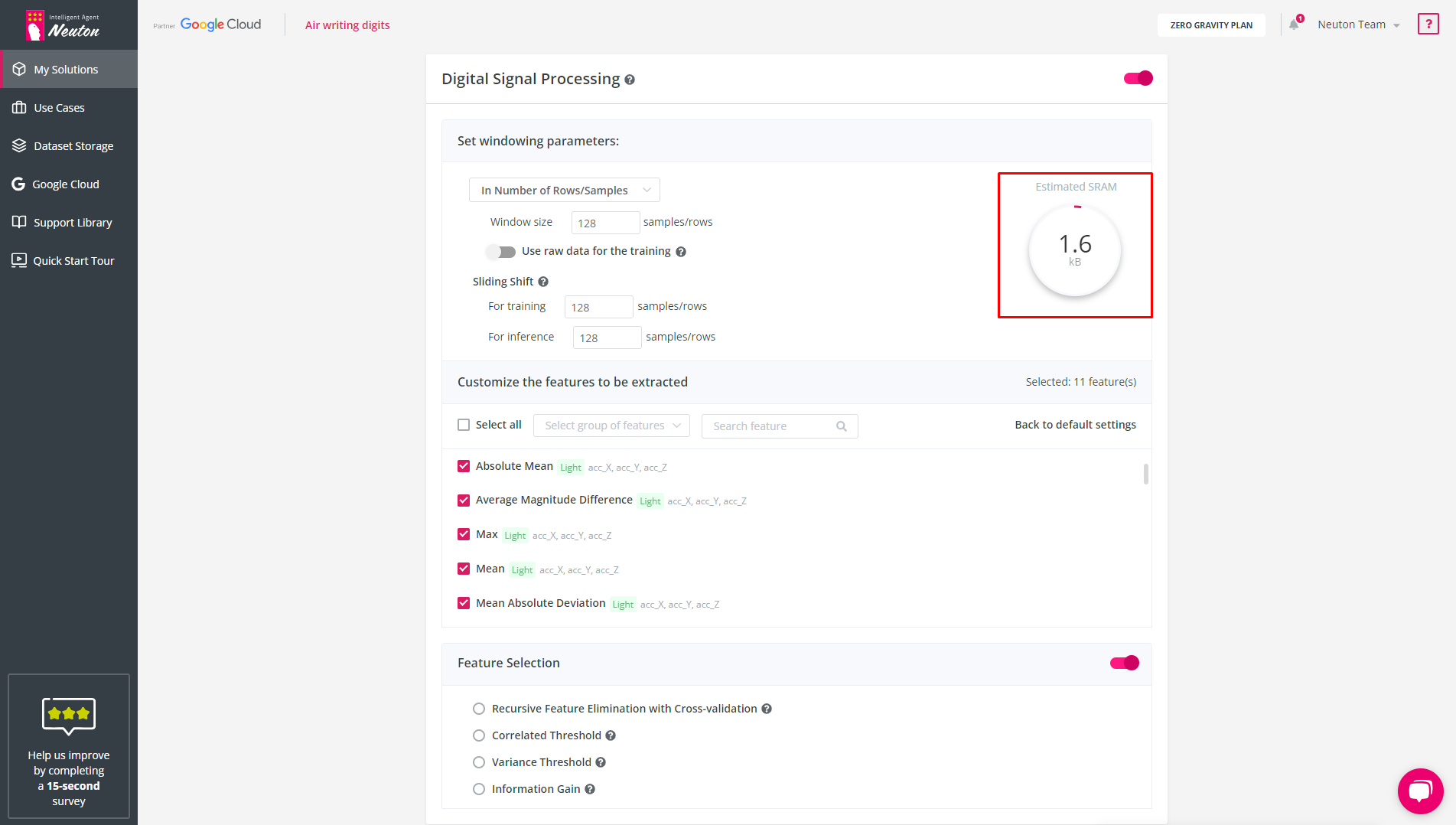
Estimated SRAM Usage
![]()
Estimated SRAM
SRAM depends on the window you choose and the list of features that will be created from the raw data. This calculation is tentative. The exact values will be computed after training the model and compiling the C libraries for specific hardware types.
If you have selected auto-detection of the window, then the estimated SRAM usage will not be calculated as the platform will determine the size of the window after the start of training.
![]()
Estimated SRAM. Auto Determination Enabled.
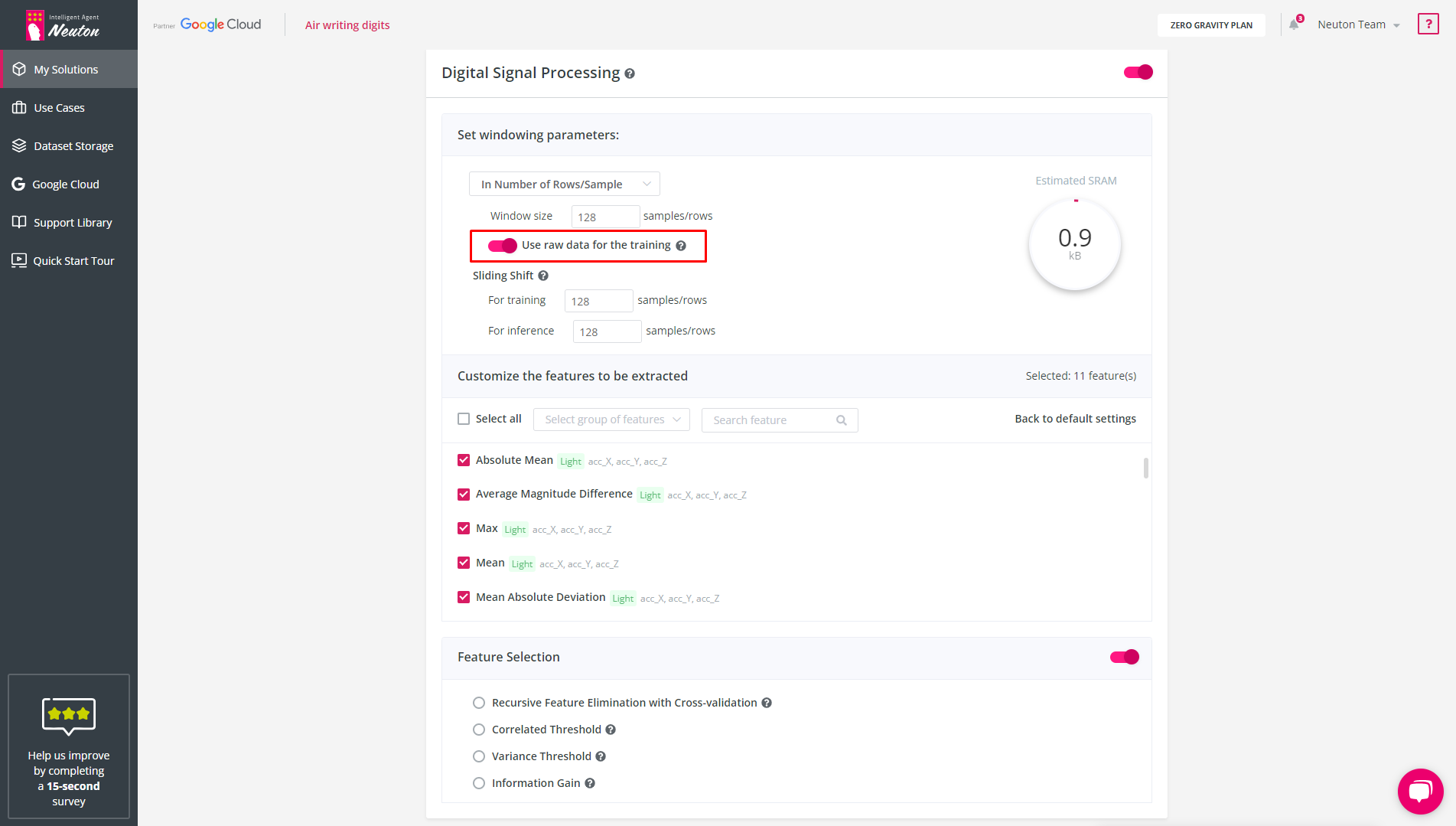
Raw Data option – Disabled by default
If you want to include raw data in training, you need to enable the function. This setting is applied to all variables/axes specified in the Feature Extraction block, i.e., you can either apply raw data for all variables/axes in the training dataset or exclude it.
The Raw Data option can't be used when the sliding shift values differ from the window size values.
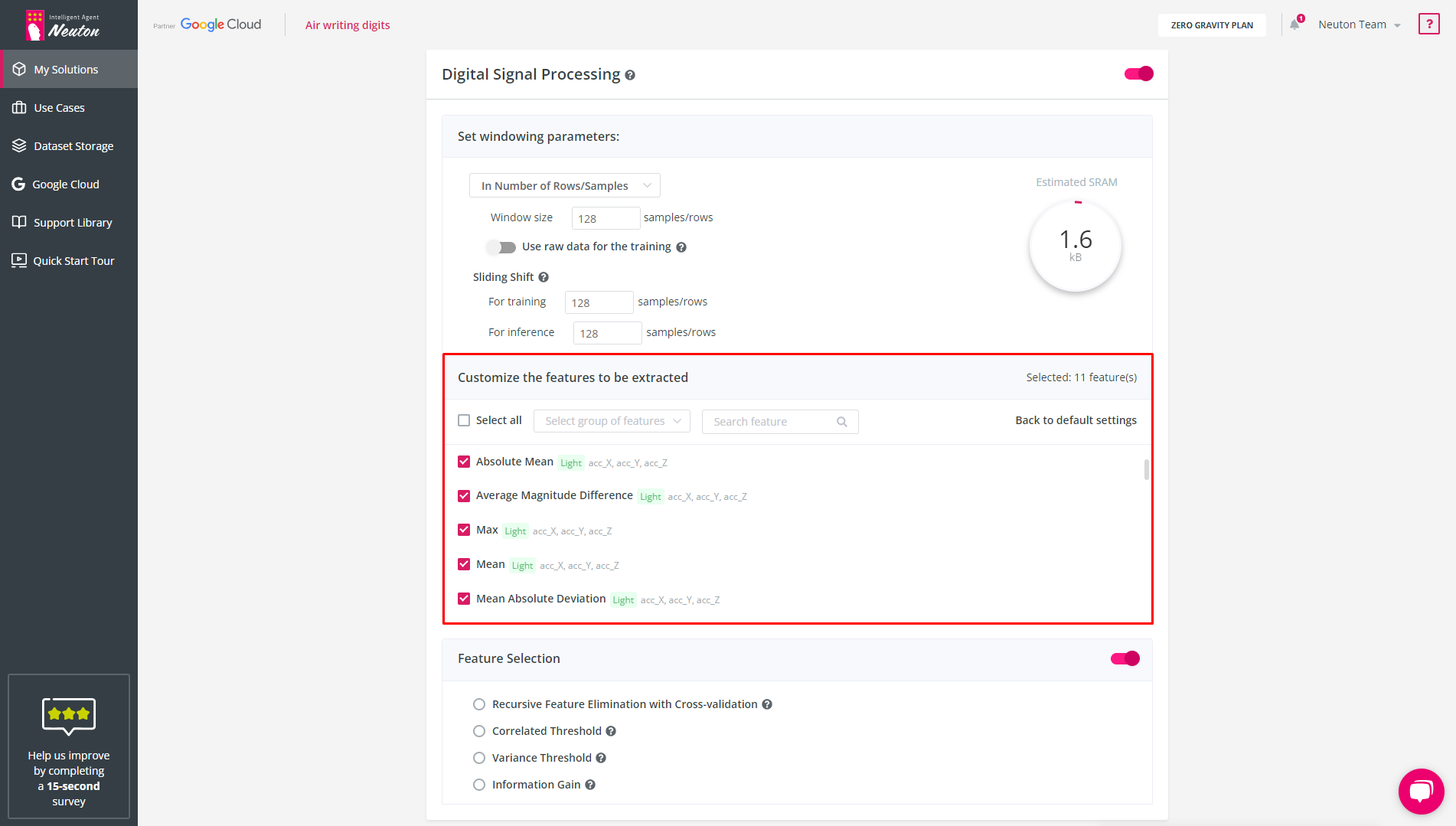
Feature Extraction
![]()
Feature Extraction
When the window size is specified, the platform automatically extracts the selected features for each column in the training dataset. The same feature extraction will be automatically executed during inference on the device. You can manage calculated features for each original variable in the training dataset by marking or unmarking the appropriate checkbox.
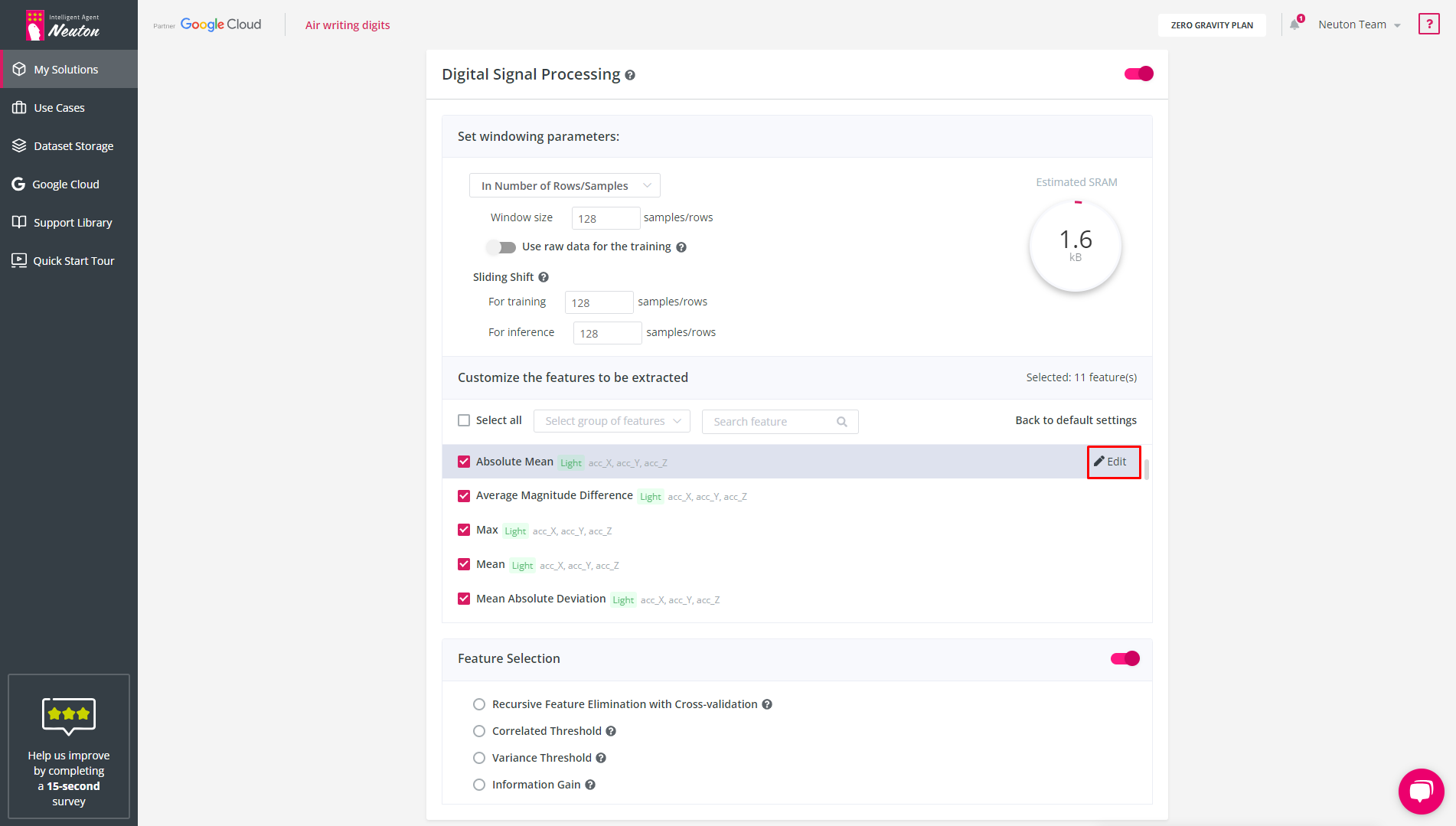
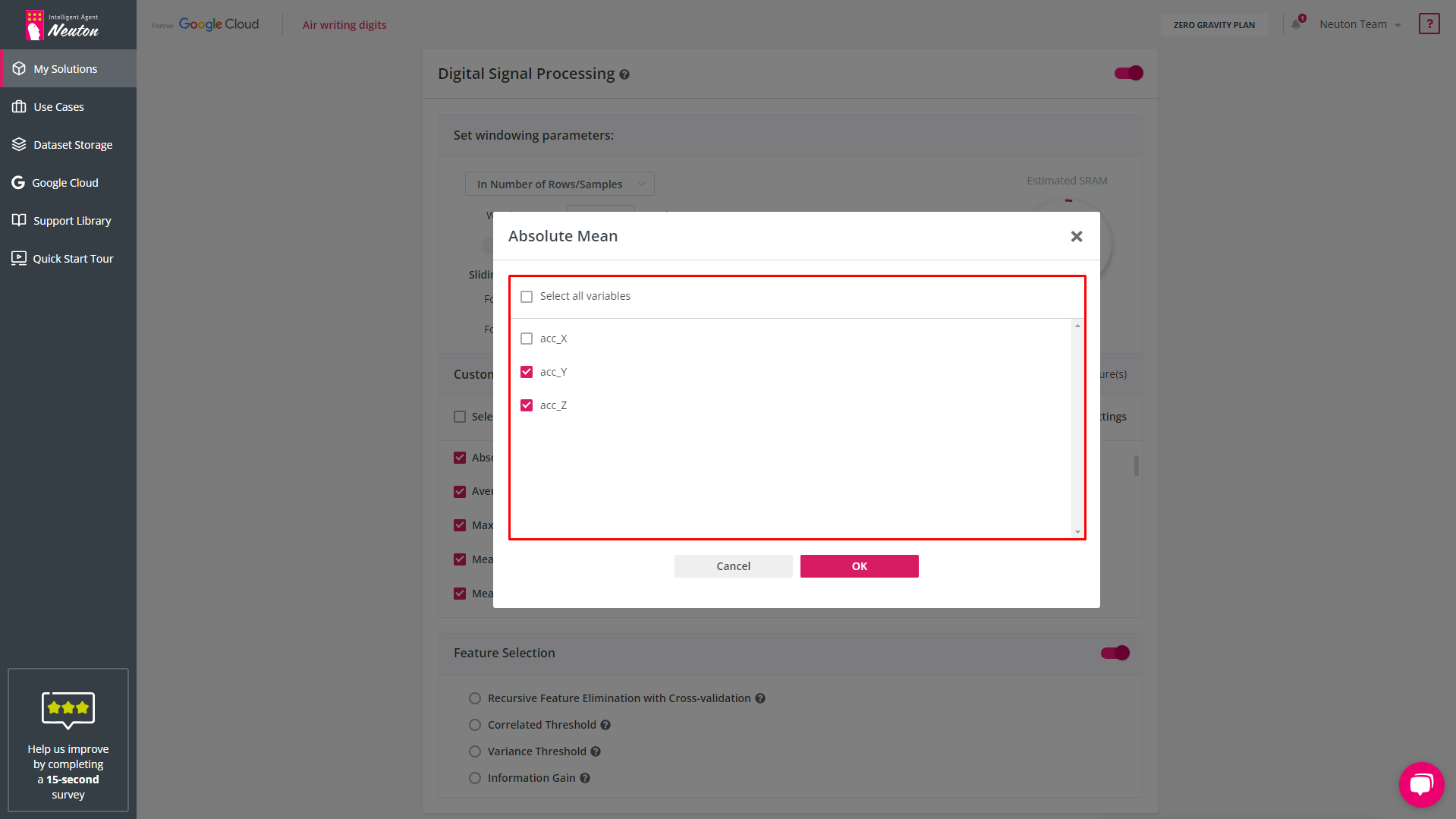
To disable a variable/axis from the Feature Extraction block, use the "Edit" button, which appears when hovering over a feature. After doing so, no feature will be created for it, and therefore it will not participate in building the model. By default, Feature Extraction uses all variables/axes.
![]()
Edit Features
![]()
Edit Features
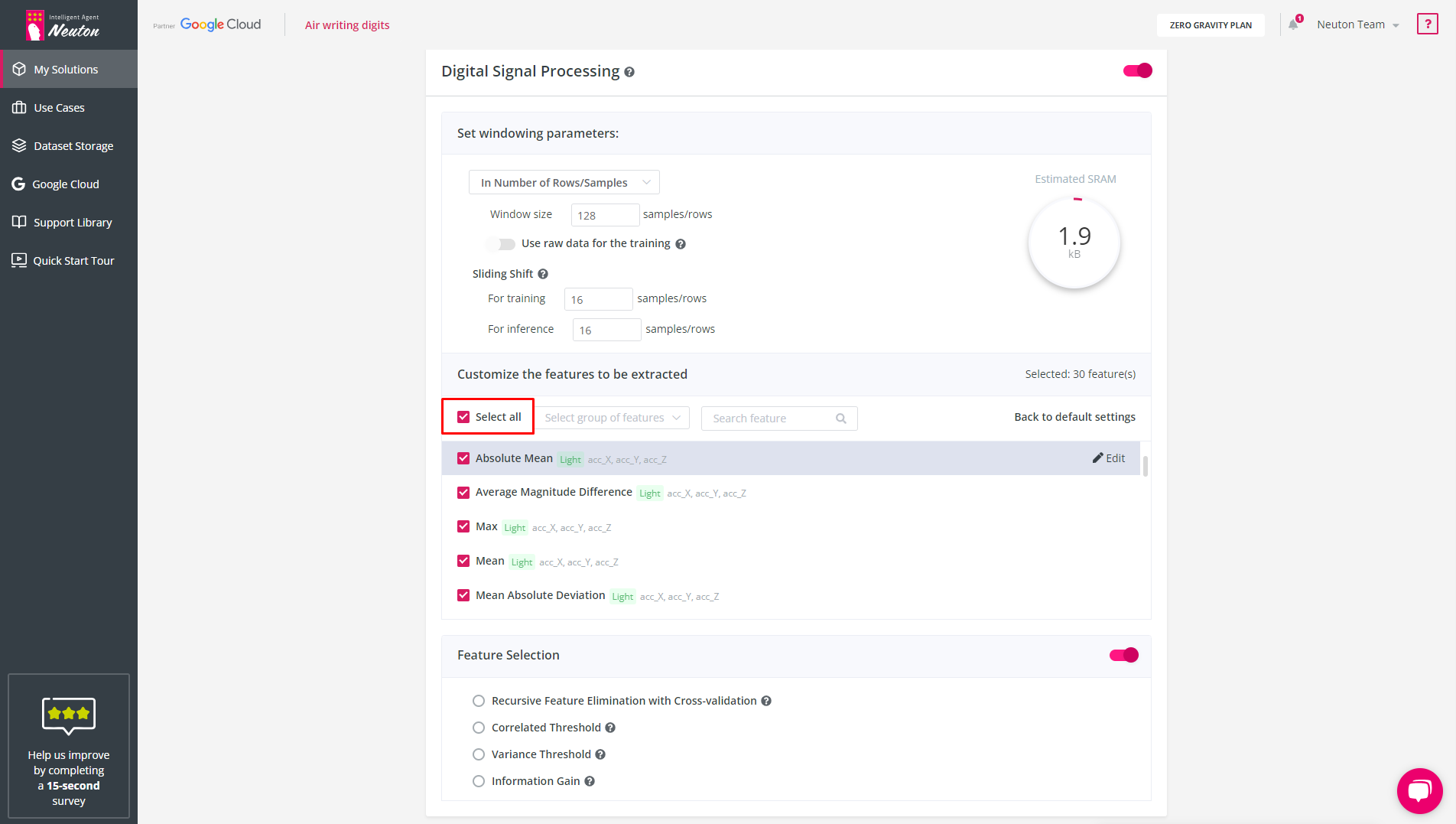
To select all the available features, you can simply click on the "Select all" button.
![]()
Select All Features
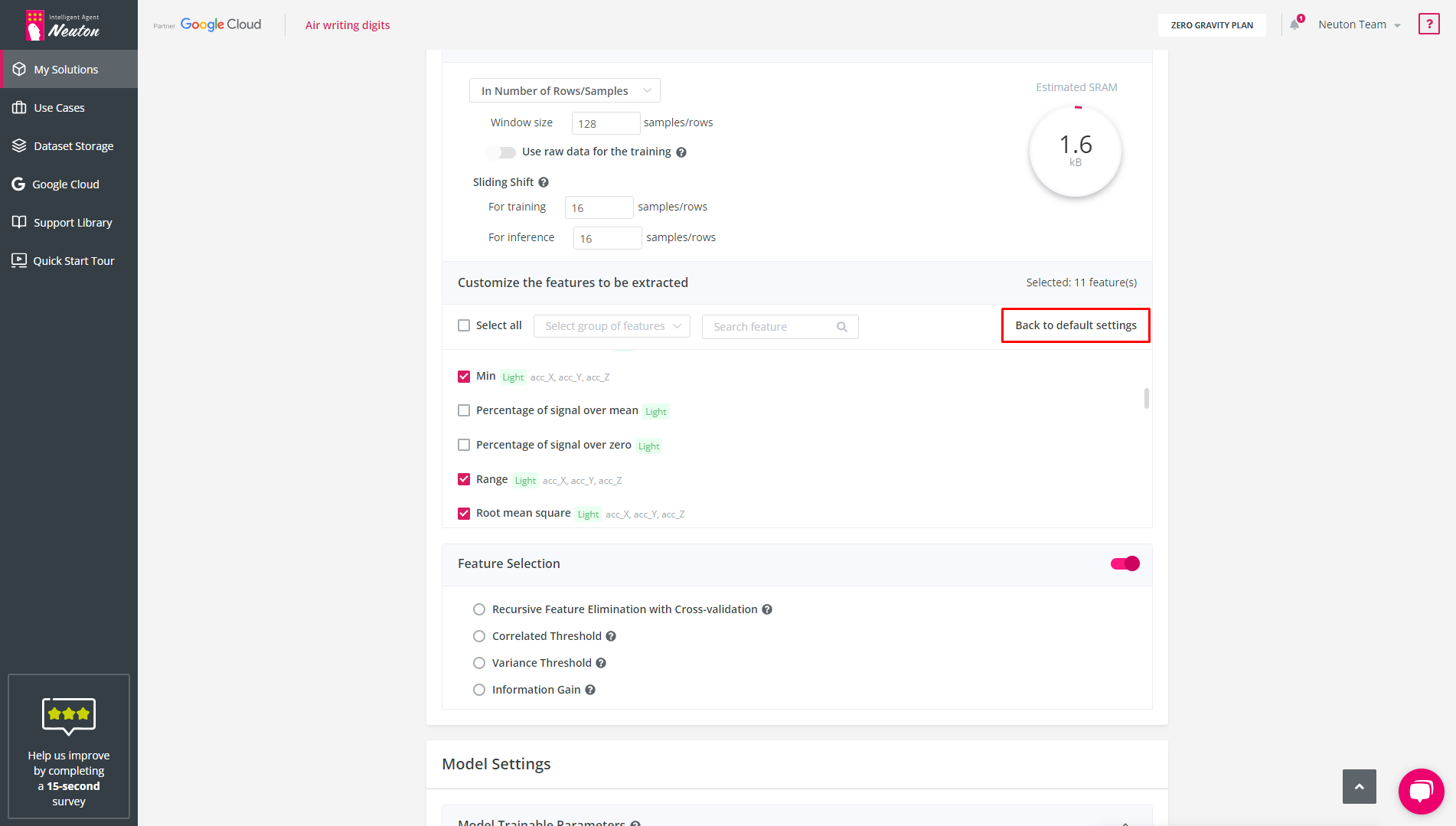
To revert back to the original settings, simply click on the "Back to default settings" button.
![]()
Back to Default Settings
The list of supported features is provided below:
Mean – Enabled by default
Max – Enabled by default
Min – Enabled by default
Root mean square – Enabled by default
Range – Enabled by default
Mean Absolute Deviation – Enabled by default
Zero-crossing rate – Enabled by default
Average Magnitude Difference – Enabled by default
Absolute Mean – Enabled by default
Standard Deviation – Enabled by default
Mean-crossing rate – Enabled by default
Threshold-crossing Rate – Disabled by default
For this parameter, the threshold is set by the user. The default value is 0. If you leave it unchanged, the feature will have the same values as the Zero-crossing Rate.
Skewness – Disabled by default
Percentage of signal over mean – Disabled by default
Percentage of signal over zero – Disabled by default
Crest factor – Disabled by default
Negative sigma crossing rate – Disabled by default
For this parameter, the Sigma Factor is set by the user. The default value is 2.
Percentage of signal over sigma – Disabled by default
For this parameter, the Sigma Factor is set by the user. The default value is 2.
Positive sigma crossing rate – Disabled by default
For this parameter, the Sigma Factor is set by the user. The default value is 2.
Root Difference Square – Disabled by default
Autocorrelation – Disabled by default
For this parameter, the Lag is set by the user. The default value is 2.
Hjorth Complexity – Disabled by default
Hjorth Mobility – Disabled by default
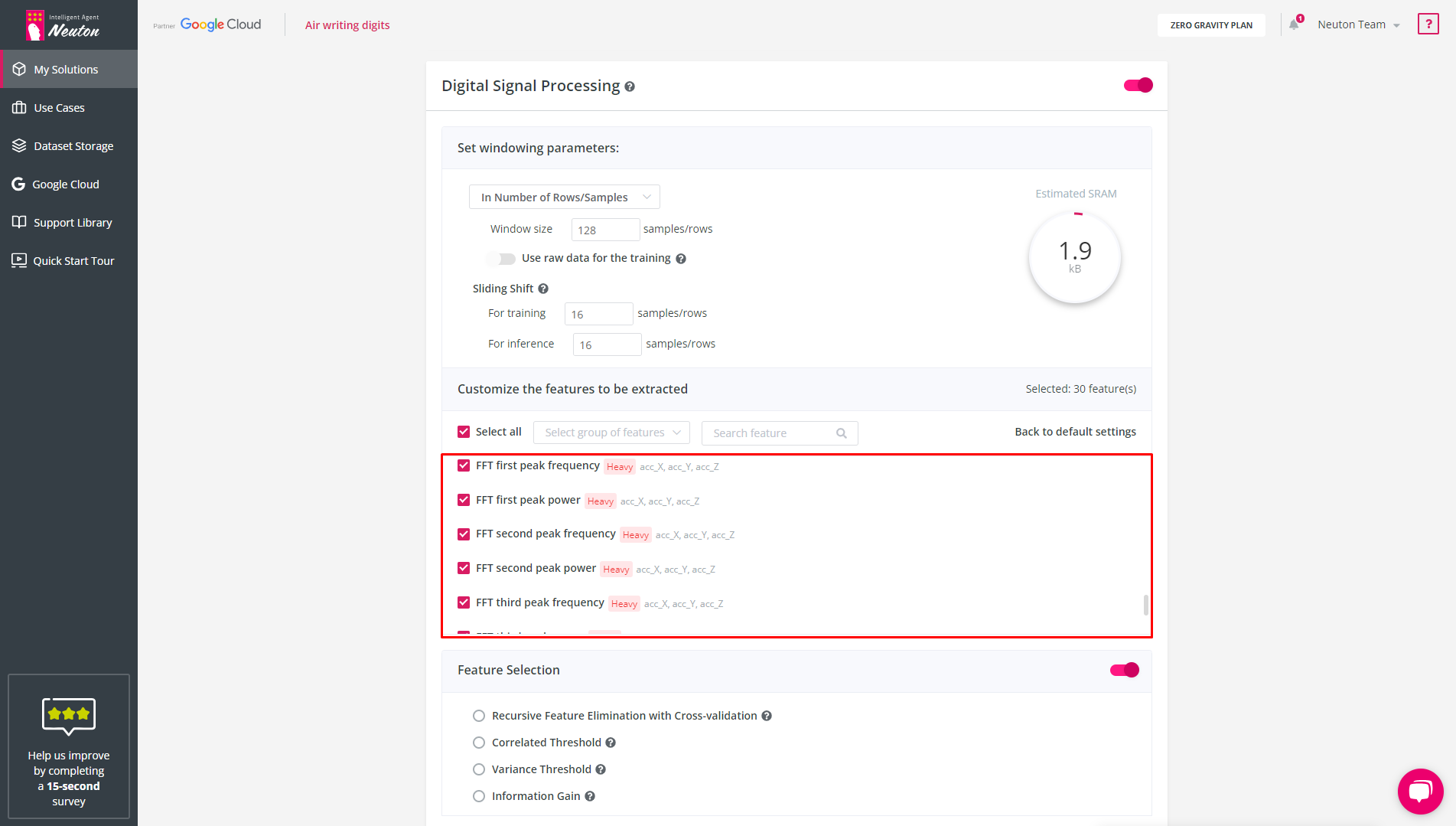
Frequency
FFT first peak power – Disabled by default
FFT first peak frequency – Disabled by default
FFT second peak power – Disabled by default
FFT second peak frequency – Disabled by default
FFT third peak power – Disabled by default
FFT third peak frequency – Disabled by default
![]()
Frequency
These functions use fast Fourier transform to calculate the frequency of peaks and their power.
If frequency features are selected the window size should be equal to the power of 2.
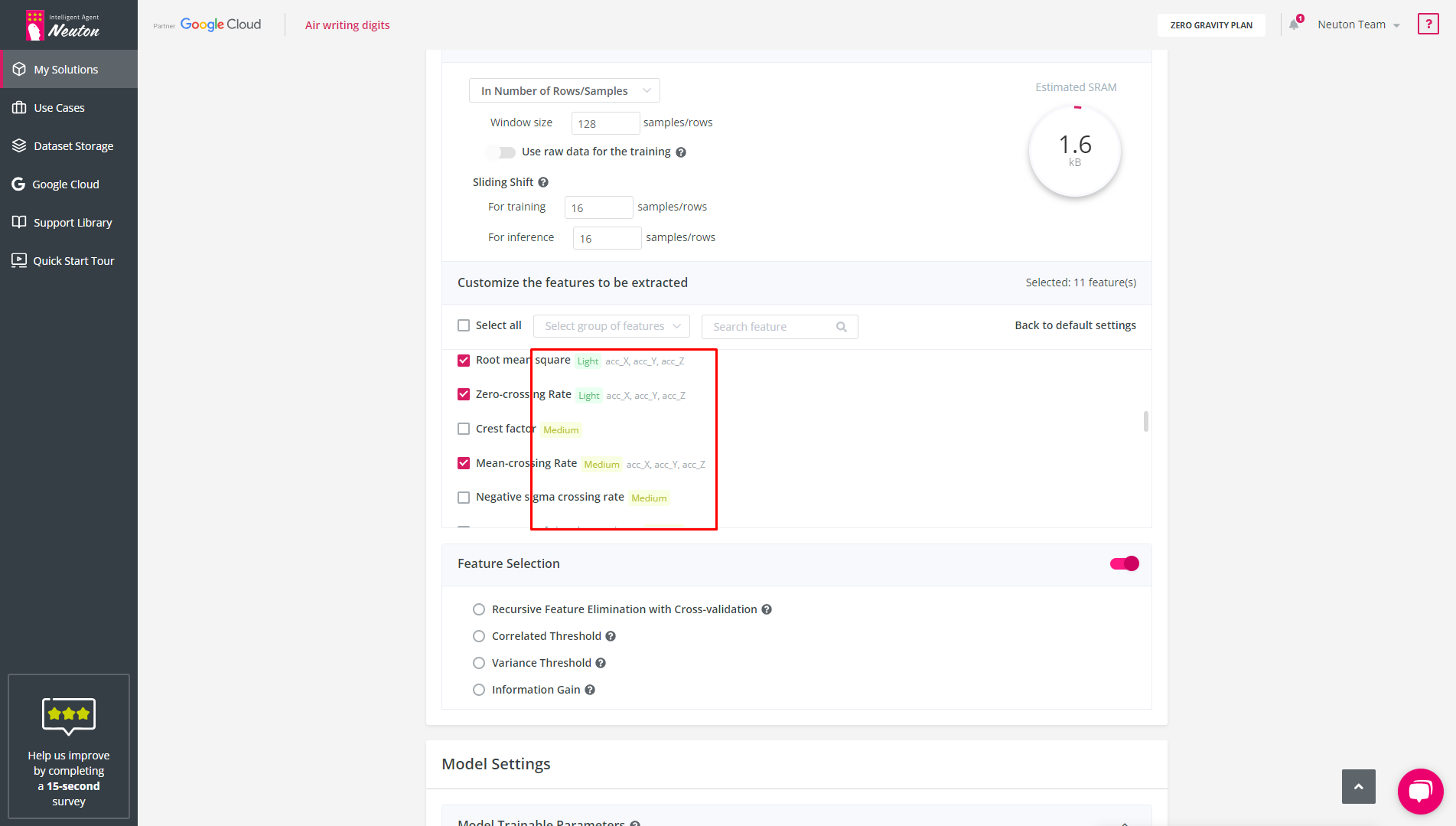
Feature complexity
Feature complexity can be classified as light, medium, or heavy, depending on the level of difficulty in its calculation. As the feature complexity increases, so does the memory requirement for its computation. Therefore, it is recommended to use only light features if you have resource-constrained devices.
![]()
Feature Complexity
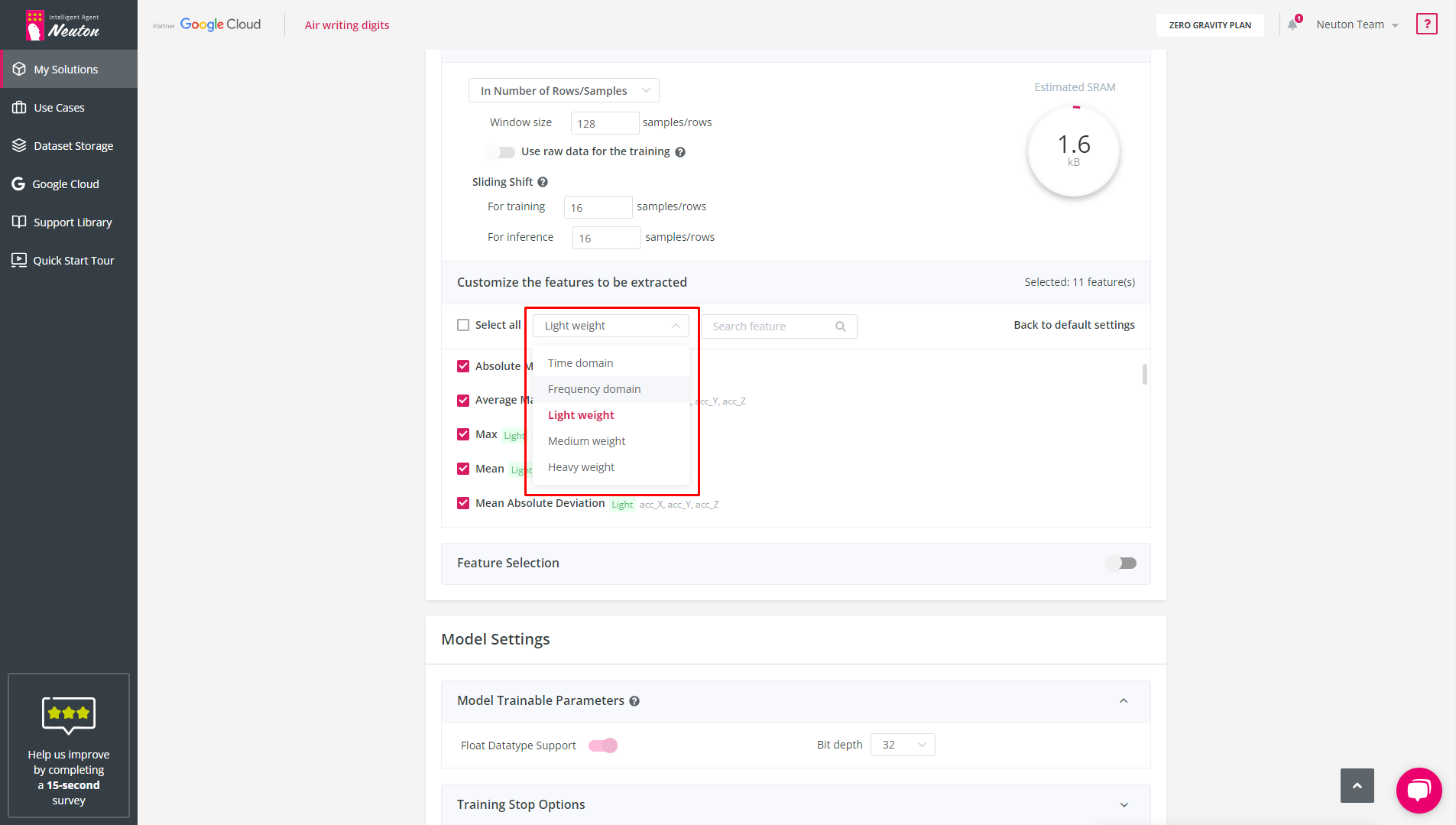
To make things easier for you, you can choose functions based on specific groups:
Time domain – Selects all features, except frequency features
Frequency domain – Selects all frequency features
Light weight – Selects all light features
Medium weight – Selects all medium features
Heavy weight – Selects all heavy features
![]()
Feature Complexity
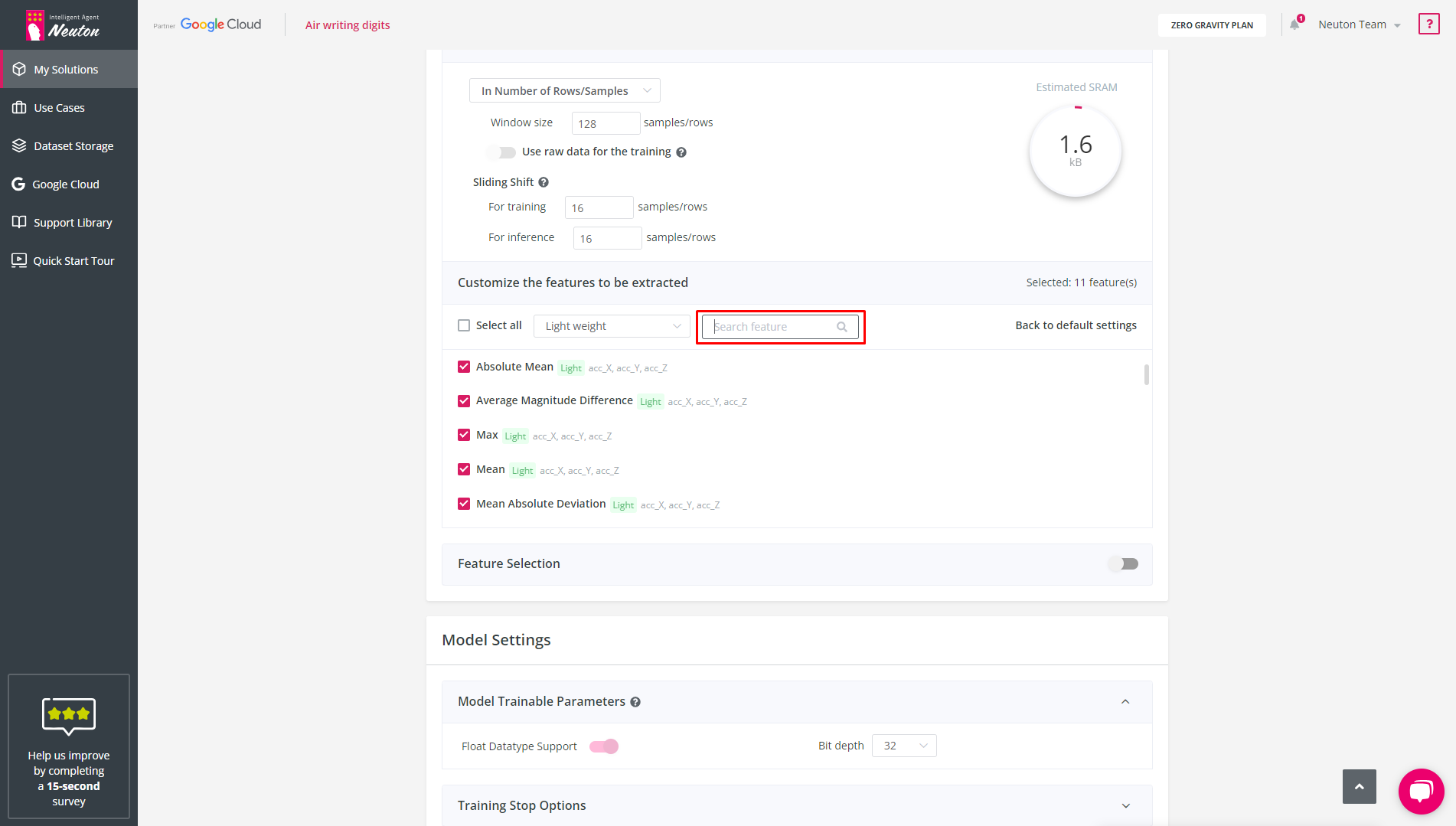
If you are looking for a particular feature, you can utilize the search bar to locate it.
![]()
Search Bar
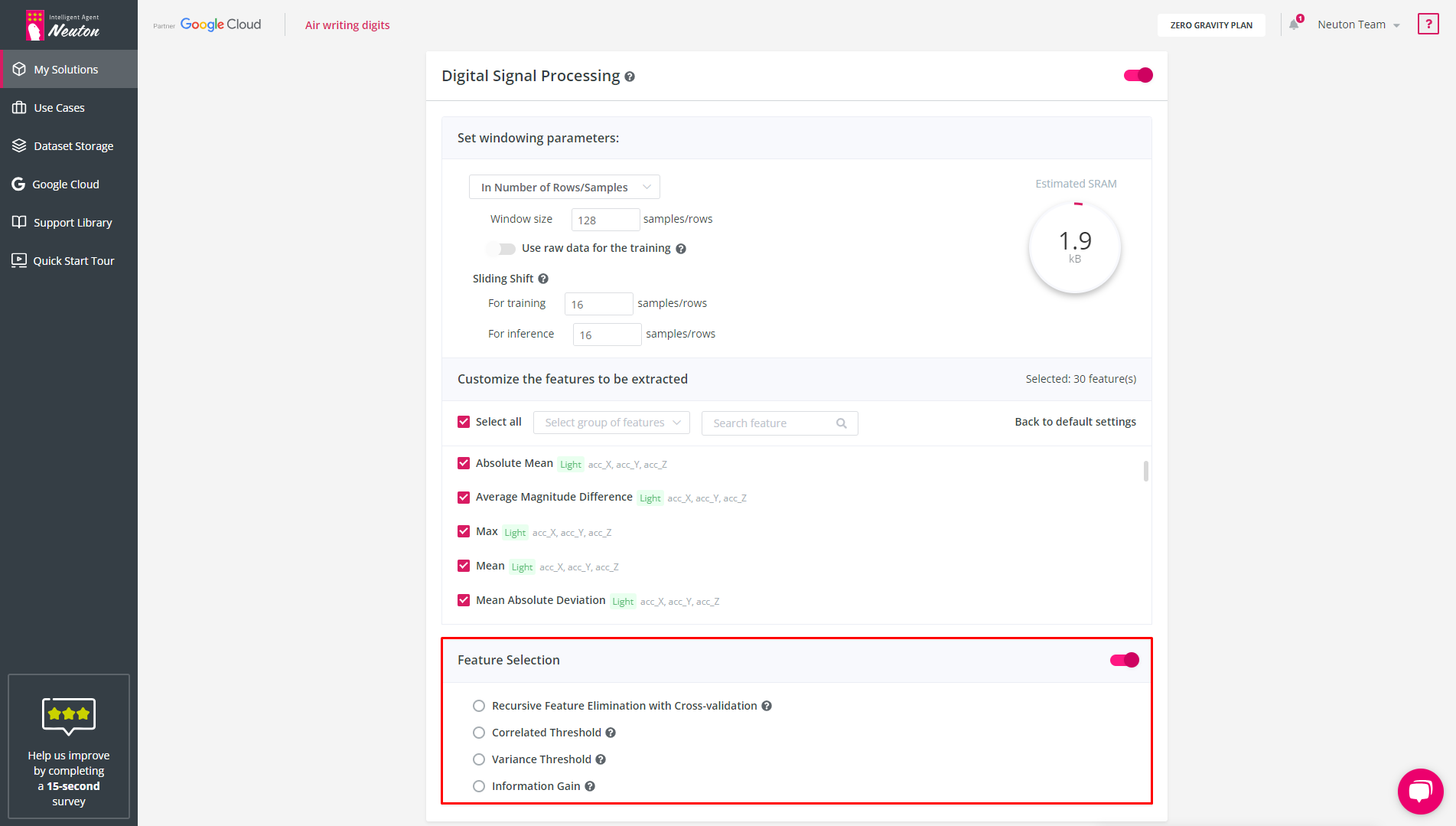
Feature Selection
The option is available only if the user has selected features in the Feature Extraction block.
Feature selection will include all created features for all variables/axes in the Feature Extraction block, except for the raw data. Therefore, if you haven’t selected any variable in the feature selection block, but the raw data option is enabled, then the feature selection block will be disabled.
The following algorithms are available for selecting features (you can choose only 1 of the methods):
Recursive Feature Elimination with Cross-validation
Eliminates features using various machine learning algorithms with cross-validation.
Correlated Threshold
Removes highly correlated features. The degree of correlation is set by the user.
Variance Threshold
Excludes features with small value fluctuations. The threshold indicates the minimal fluctuation value for excluding unimportant variables.
Information Gain
Ranks all features according to the degree of influence on the target variable and leaves only the most significant ones. You set the number of features that should be left in the train dataset.
![]()
Feature Selection