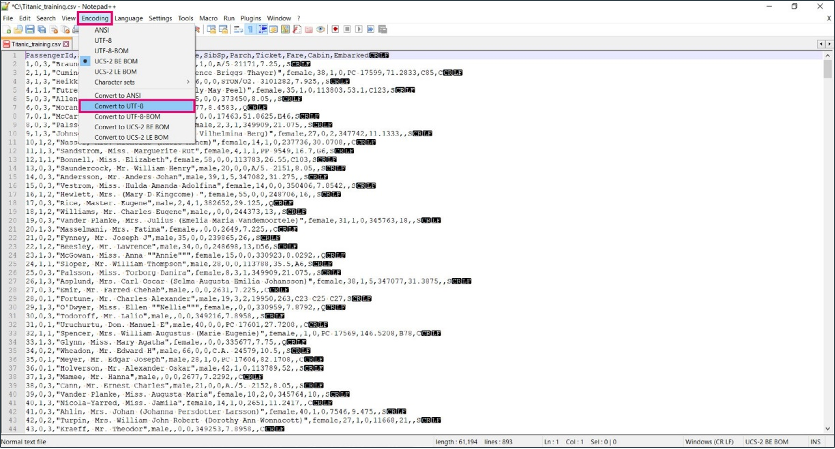
The requirements below are provided for training and test (holdout) datasets. Meeting these requirements will guarantee successful model training and prediction on the new data. We recommend using a text editor like Notepad++ to check the datasets.
A dataset must be a CSV file using UTF-8 or ISO-8859-1 encoding.
The file name must not contain the following characters: !/[+!@#$%^&*,. ?":{}\\/|<>()[]]
All feature values in the dataset must be numeric. For the classification task type, values of the target variable should start with 0.</span >
A dataset must not have any empty values or values which represent empty values like “NA”, “NAN”, etc.
A comma, semicolon, pipe, caret, or tab must be used as a separator. CRLF or LF should be used as the end-of-line character. The separator and end-of-line character should be consistent inside the dataset.
All column names (values in the CSV file header) must be unique and must contain only letters (a-z, A-Z), numbers (0-9), hyphens (-), or underscores (_).
For the classification task type, a training dataset must have a minimum of 2 classes of target variable with at least 20 samples provided for each class.
Currently, Neuton supports only the EN-US locale for numbers, so:
You must use a dot as a decimal separator, and delete spaces and commas typically used to separate every third digit in your numeric fields. For example – "20,000.00" should be replaced with "20000.00"
If any numeric column is represented as a combination of a number and its corresponding unit, then only the number should be placed in the column. For example – "$20,000.00" should be replaced with "20000.00"
Date/time columns must be in epoch time representation or relative date format. For example, “10/18/2017” should be represented as “1508284800”.
In test datasets, the same timestamp format should be used in a manner consistent with the training dataset.
End-of-line symbols must be excluded from the field values.
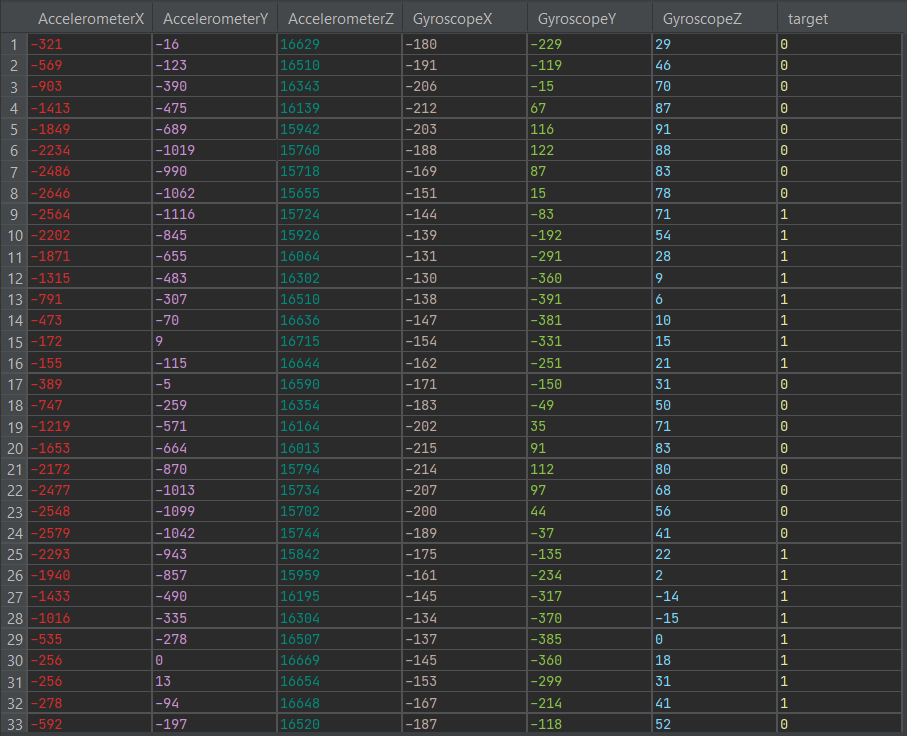
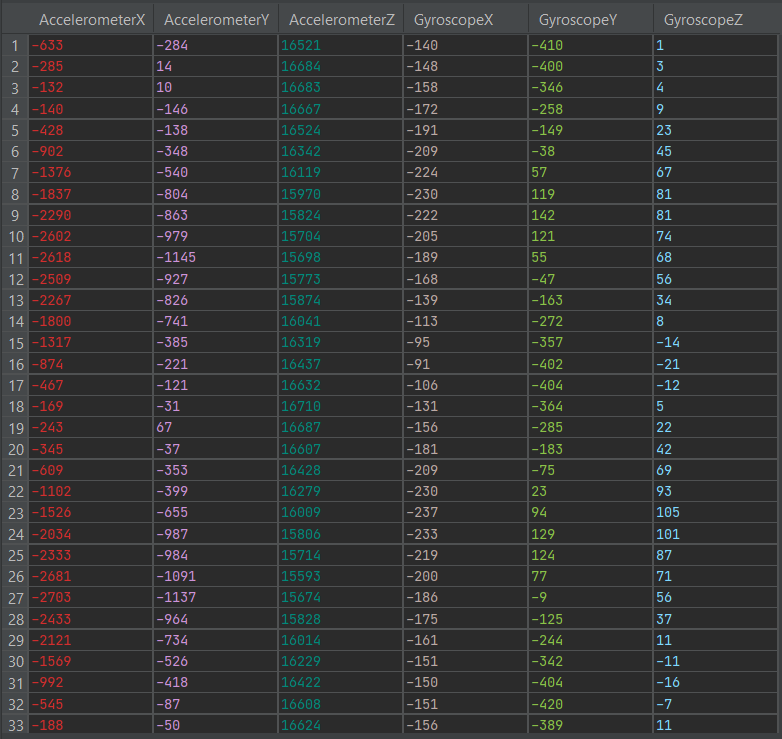
In the case of sensor data from gyroscopes, accelerometers, magnetometers, electromyography (EMG), and other similar devices for creating models using Digital Signal Preprocessing, every row of a dataset should be device readings per unit of time with a label as a target. You should not shuffle signal labels or encode your signal for model creation.
For example, if the window is 8, then the dataset can be organized as follows:
The number of lines must be excluded from the training dataset.
Data can be represented in the following types: INT8, INT16, FLOAT 32