The Neuton Platform enables fast and seamless creation of optimal models,
offering a high level of automation in data processing and neural network pipeline generation.
In addition, the platform significantly optimizes cloud resource usage.
Below you will find an overview which showcases the core components that Neuton leverages in its workflow to provide exceptional results.
Below you will find an overview which showcases the core components that Neuton leverages in its workflow to provide exceptional results.

Google cloud
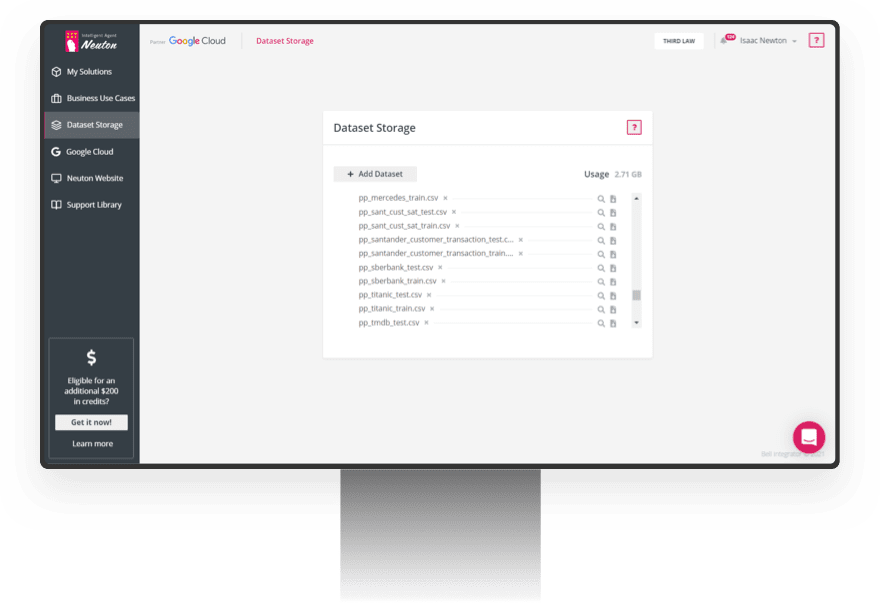
Automated Storage Provisioning
The platform automatically executes provisioning and de-provisioning of storage for each respective model to ensure maximum data security.
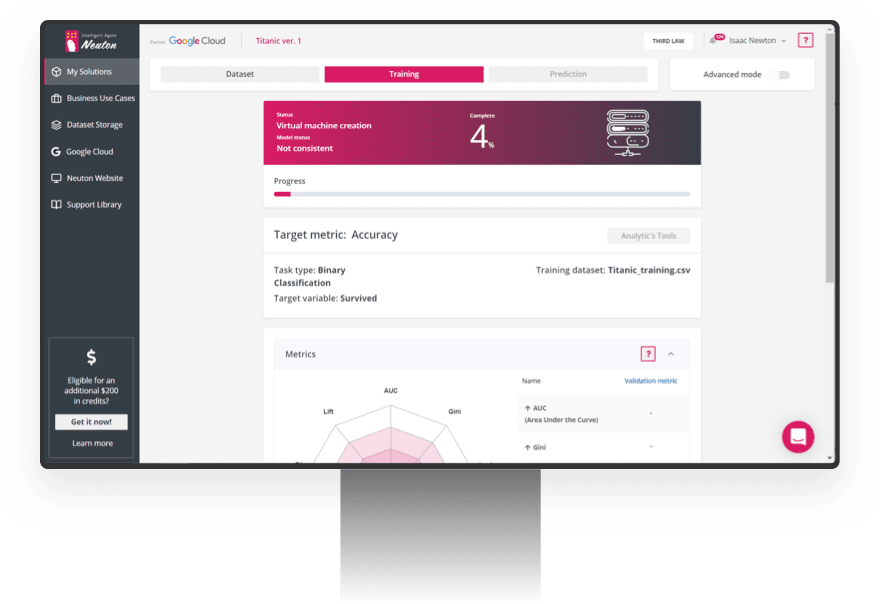
Automated Virtual Machine Provisioning
During both the training and prediction phases, the platform automatically executes provisioning
and deprovisioning of virtual machines with the most suitable configurations, based on dataset
parameters.
During the prediction phase, virtual machine usage/time is controlled by the user through a
user-friendly interface.